Could Two Random UUIDs Ever Collide? The Surprising Math Behind Unique IDs
Every UUID is a bet that a random string has never existed before, anywhere, without checking with anyone. It sounds reckless — here's the staggering math that makes it one of the safest bets in compu
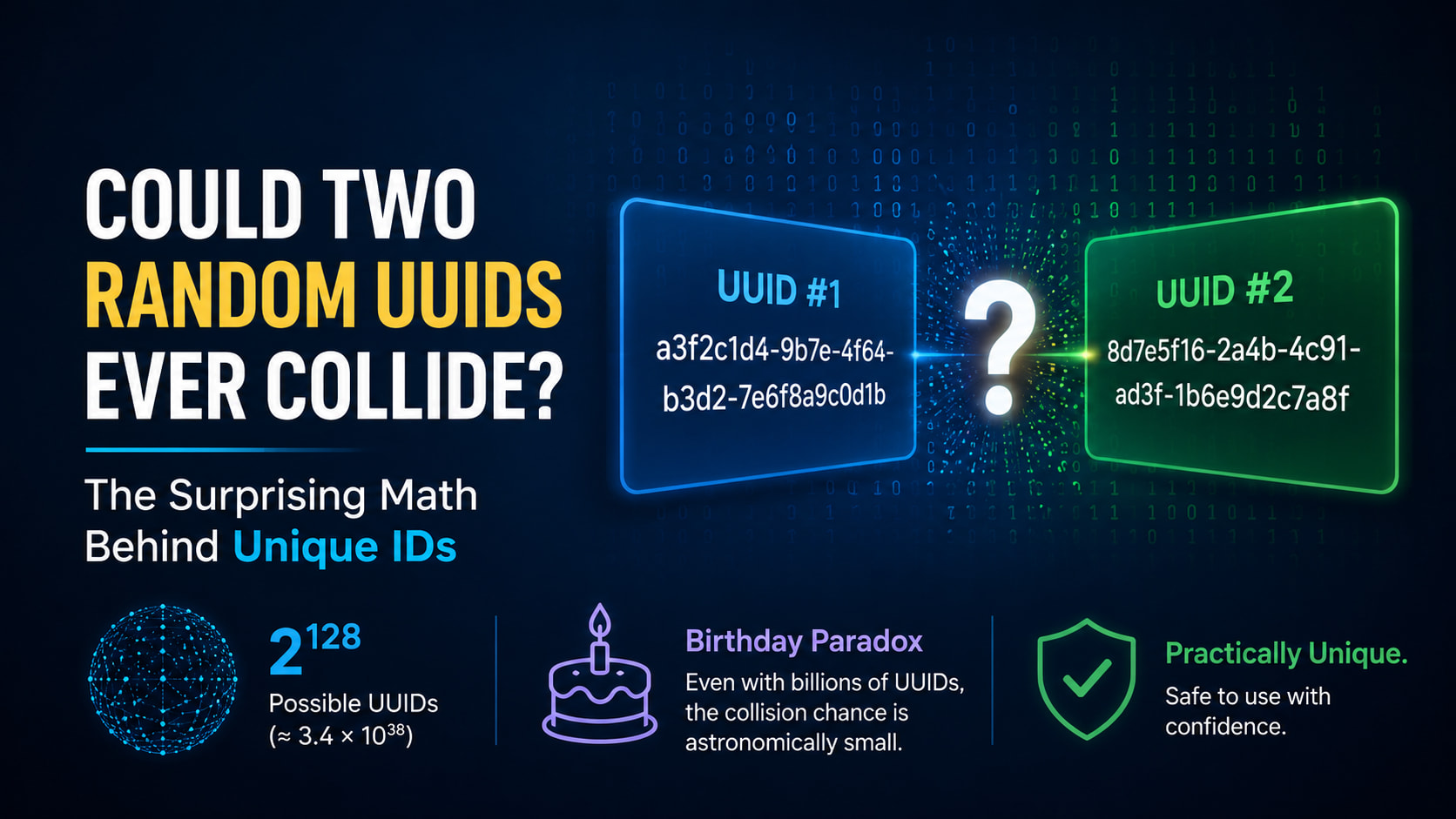
There's a number that powers a staggering amount of modern software, and almost everyone who uses it quietly worries about the same thing: what if it isn't actually unique? Every time a program mints a UUID — for a new user, a file, a database row, a payment — it's making a bold bet that the random-looking string it just produced has never existed before and never will again, anywhere on Earth, without checking with anyone. It feels reckless. It is, in fact, one of the safest bets in computing.
To see why, you have to play with the numbers, and the numbers are genuinely staggering. But the story of why we trust randomness this much — and the clever ways UUIDs are built — is even better than the math.
What a UUID actually is
A UUID, or Universally Unique Identifier (Microsoft calls its version a GUID — same thing), is a 128-bit value. You almost always see it as 32 hexadecimal characters split into five groups: 8-4-4-4-12, like f47ac10b-58cc-4372-a567-0e02b2c3d479. Those 128 bits are the whole point. They give you an address space so vast that you can hand out identifiers at random and simply assume no two will ever match.
The most common kind, version 4, isn't fully random, though — a few bits are reserved. Specifically, one digit always marks the version (how the UUID was made) and a couple of bits mark the variant (which standard it follows). That leaves 122 bits of pure randomness. You can see exactly which digits are fixed by generating one in a UUID generator and looking at the highlighted version and variant positions — everything else is a coin flip.
The number that makes collisions a non-issue
122 random bits means 2¹²² possible version-4 UUIDs. Written out, that's about 5,300,000,000,000,000,000,000,000,000,000,000,000 — roughly 5.3 undecillion. It's a number with no intuitive handle; it dwarfs the count of grains of sand on Earth, and comfortably exceeds the estimated number of stars in the observable universe.
But raw possibilities aren't the right question. The honest question is the birthday problem: not "how many UUIDs exist," but "how many do you have to generate before two of them accidentally match?" The birthday paradox — the surprising fact that just 23 people in a room give a 50% chance two share a birthday — tells us collisions arrive far sooner than the total space suggests. For UUIDs, the threshold sits at roughly the square root of the space, around 2.7 × 10¹⁸ identifiers, before you reach even a 50% chance of a single clash.
That still sounds finite, until you translate it into effort. If you generated one billion UUIDs every second, without pause, it would take you around 85 years to accumulate enough for a coin-flip's chance of one collision. To get a one-in-a-billion chance of a collision, you'd need to produce something like 100 trillion of them. No real application generates IDs anywhere near these rates, which is why engineers treat v4 UUIDs as unique without a second thought — the failure probability is so far below other risks (a cosmic ray flipping a bit in memory, the database catching fire) that it rounds to zero.
Where UUIDs came from
This trick wasn't obvious, and it has a real history. UUIDs were born in the 1980s at a company called Apollo Computer, as part of its Network Computing System — a way for distributed machines to label things without a central registry handing out numbers. The idea passed into the Open Software Foundation's Distributed Computing Environment, and from there Microsoft adopted it enthusiastically as the GUID, scattering them throughout Windows and its COM component system.
The format was finally pinned down as an internet standard in RFC 4122 in 2005, which defined the versions most developers know. In 2024 it was modernized by RFC 9562, which added newer versions built for today's problems — most notably version 7. So the humble UUID is both decades old and actively evolving.
The virus that got caught by a UUID
Here's where the history takes a genuinely cinematic turn. The earliest UUIDs, version 1, were built from a timestamp plus the computer's network card address — its MAC address, a number unique to that physical hardware. It made the UUID guaranteed-unique, but it also quietly stamped every ID with a fingerprint of the machine that made it.
In 1999, that detail helped catch a criminal. The Melissa virus tore through email systems worldwide, and investigators discovered that documents involved carried embedded GUIDs — which, in that era, contained the MAC address of the computer that created them. That hardware fingerprint became a thread investigators could pull, contributing to the identification and arrest of the virus's author. A "unique identifier" turned out to be a little too identifying. It's a perfect, slightly chilling reminder that the way you generate an ID can leak more than you intend — and a big reason version 4, which is purely random and reveals nothing about your machine, became the default.
Not all UUIDs are random — and that's on purpose
Once you know the versions, the UUID stops being a single thing and becomes a small toolkit:
Version 4 is the random workhorse. Reveals nothing, collides effectively never, perfect for almost everything.
Version 1 is timestamp-plus-node, the original. Mostly historical now, given the privacy lesson above.
Version 5 is the clever oddball: it's deterministic. Feed it a "namespace" and a name, and it returns the SHA-1-derived UUID for that combination — and the same inputs always yield the same UUID. That's invaluable when you need a stable, reproducible ID for something (a URL, a filename) without storing a lookup table. Generate a v5 for example.com today and in ten years and you'll get the identical value.
Version 7 is the modern star, and it solves a problem v4 accidentally creates. Because v4 is fully random, consecutive IDs are scattered everywhere, which is rough on databases: when a UUID is a primary key, random values force the database's index to insert all over the place, fragmenting it and slowing writes. Version 7 fixes this by starting each UUID with a Unix-millisecond timestamp, so newly created IDs sort in roughly the order they were made. New rows append neatly to the end of the index instead of scattering. For new systems choosing a primary-key format, v7 increasingly wins — you keep the uniqueness of a UUID and regain the friendly ordering of an auto-incrementing number. You can compare the two side by side in a UUID generator: notice how a batch of v7s share a common prefix that creeps upward, while v4s look like pure noise.
A word of caution: unique is not secret
Because UUIDs look like random gibberish, people occasionally reach for them as passwords, API keys or unguessable secret links. That's a mistake worth flagging. A UUID is an identifier, not a credential. v1 and v7 contain a predictable timestamp; even v4, while not feasibly guessable, was designed for uniqueness rather than to resist a determined attacker, and many libraries historically didn't use a cryptographically secure random source. If you need a secret, generate one explicitly for that purpose. If you need a unique label, a UUID is exactly the right tool. (Good news: a modern generator uses the browser's cryptographically secure randomness for the random parts, but the principle still stands — uniqueness and secrecy are different jobs.) The practical rule of thumb: it's fine for a UUID to appear in a URL, a log file or a database row where anyone might see it; it's never fine for it to be the only thing standing between a stranger and someone's account or data. Treat it as a name tag, not a key.
So, could two UUIDs ever collide?
Technically, yes. Practically, no — not in any system you'll ever build or use. The math puts the odds so far beyond astronomical that the rest of your stack will fail thousands of times over before a UUID collision becomes a realistic worry. That's the quiet genius of the whole scheme: by making the space of possibilities absurdly large, you get to skip coordination entirely. Two servers on opposite sides of the planet, never having spoken, can each mint millions of IDs and trust they'll never tread on each other.
It's a beautiful trade — a few wasted bits of entropy in exchange for never needing a central authority, a lock, or a lookup. The next time your code casually generates one of these 36-character strings and assumes it's one of a kind, you'll know it isn't faith. It's arithmetic. And if you ever want to watch the machinery at work — random v4s, time-ordered v7s, deterministic v5s, and the version and variant digits that hold it all together — you can generate and dissect them yourself with a free UUID generator.
